아래 링크 내용에 이어지는 내용이다.
Haproxy, Keepalived 란?
※ 사전내용 ※ 1. 로드 밸런싱 - 서버가 처리해야 할 요청이 많을 경우, 요청을 여러 서버에 분배해주는 것 2. 로드 밸런서가 필요한 이유와 방법 - 요청이 많아짐에 따라, 서버에는 더 많은 부하
jparkk.tistory.com
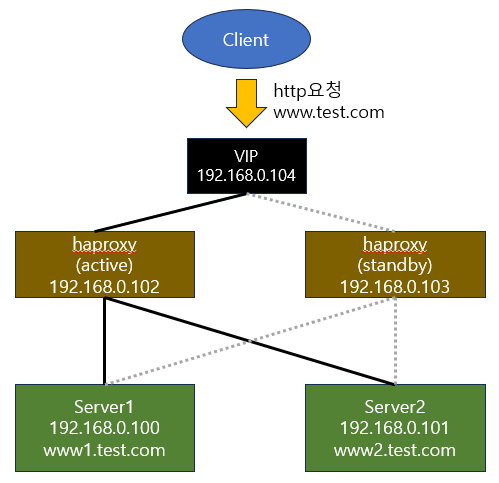
Haproxy+Keepalived 서버 (active/standby) 구성하기
실행환경 : CentOS Linux release 7.9.2009 (Web1~2, Haproxy active, Haproxy standby)
1. 패키지 설치
yum 명령어로 설치한다.
[01:03:16][root@haproxy_active_svr ~]
$ yum install haproxy keepalived패키지 설치 확인 및 버전 확인
[01:08:27][root@haproxy_active_svr /]
$ haproxy -version
HA-Proxy version 1.5.18 2016/05/10
Copyright 2000-2016 Willy Tarreau <willy@haproxy.org>
[01:08:31][root@haproxy_active_svr /]
$ keepalived -version
Keepalived v1.3.5 (03/19,2017), git commit v1.3.5-6-g6fa32f2
Copyright(C) 2001-2017 Alexandre Cassen, <acassen@gmail.com>
2. Keepalived 설정하기
1) keepalived.conf 설정하기(master)
global_defs {
router_id haproxy_active # id 지정
}
vrrp_instance VI_1 {
state MASTER # master 역할이니, master로 지정
interface eth0 # VIP를 추가할 인터페이스명을 지정
virtual_router_id 10 # id 지정
priority 200 # priority값을 지정, 값이 높으면 master
advert_int 1
authentication {
auth_type PASS # Master-Standby 서버 동일하게 적용
auth_pass 1111 # Master-Standby 서버 동일하게 적용
}
virtual_ipaddress {
192.168.0.104 #VIP를 지정
}
}
2) Active 서버에서 VIP가 적용되었는지 확인
$ ip ad
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:39:48:f5 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.102/24 brd 192.168.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet 192.168.0.104/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fe39:48f5/64 scope link
valid_lft forever preferred_lft forever
3) keepalived.conf 설정하기(standby)
global_defs {
router_id haproxy_standby # id 지정
}
vrrp_instance VI_1 {
state BACKUP # BACKUP 역할이니, BACKUP로 지정
interface eth0 # VIP를 추가할 인터페이스명을 지정
virtual_router_id 10 # id 지정
priority 100 # priority값을 지정, 값이 높으면 master
advert_int 1
authentication {
auth_type PASS # Master-Standby 서버 동일하게 적용
auth_pass 1111 # Master-Standby 서버 동일하게 적용
}
virtual_ipaddress {
192.168.0.104 #VIP를 지정
}
}
4) Standby 서버에서 VIP 적용 확인
→ Standby 서버이므로, VIP가 뜨지 않는게 정상.
→ 단, Master서버의 keepalived를 stop하고 VIP가 뜨면 정상
$ ip ad
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:2b:e8:84 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.103/24 brd 192.168.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fe2b:e884/64 scope link
valid_lft forever preferred_lft forever
3. Haproxy 구성하기
→ Haproxy 설정은 /etc/haproxy/haproxy.cfg에서 한다.
→ Active - Standby 모두 동일하게 설정을 적용하면 된다. 단, Listen 부분의 IP는 각 서버의 IP로 넣는다.
→ 각 버전에 맞는 매뉴얼은 이 URL을 참고하면 설명이 되어 있다.
1) haproxy.cfg 파일 설정 적용하기
- global : 전체 영역에 걸쳐서 적용되는 설정
- defaults : 다음 파트들(frontend, backend, listen)에 대한 변수를 설정한다.
- frontend : 클라이언트의 요청이 연결될 ip 및 port를 설정
- backend : frontend에서 들어온 트래픽을 전달할 프록시 서버들에 대한 설정, healthcheck 설정
- listen : 모니터링 및 통계 페이지 설정
#===========================================
# global 영역
# 전체 영역에 걸쳐서 적용되는 설정
#===========================================
global
log 127.0.0.1 local2 # 로깅 설정
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000 # 프로세스당 최대 동시 연결 수 지정
user haproxy
group haproxy
daemon # 데몬 모드
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#===========================================
# default 영역
# 다음 파트들(frontend, backend, listen)에 대한 변수를 설정한다.
#===========================================
defaults
mode http # 인스턴스의 실행 모드 또는 프로토콜 설정
log global # 로깅 활성화
option httplog # HTTP 요청, 세션 상태 및 타이머 로깅 사용
option dontlognull # null 연결 로깅 사용 또는 사용 안 함
option http-server-close # 서버 측에서 http 커넥션 종료를 사용
retries 3 # 연결 실패 후, 재시도 횟수
timeout http-request 10s # 완전한 HTTP 요청을 대기할 수 있는 최대 허용 시간
timeout queue 1m # 커넥션 슬롯이 비워질 때까지 대기열에서 대기할 최대 시간 설정
timeout connect 10s # 서버에 대한 연결 시도가 성공할 때까지 대기할 최대 시간을 설정
timeout client 1m # 클라이언트 측에서 최대 비활성 시간을 설정합니다.
timeout server 1m # 특정 시간 이상 활동이 없으면 서버가 연결을 끊는다.
timeout http-keep-alive 10s # 새로운 http 연결이 나타날 때까지 기다리는 최대 시간 설정
timeout check 10s # 이미 연결된 이후에만, 추가적인 check timeout 시간을 설정한다.
maxconn 3000 # 프로세스당 최대 동시 연결 수 지정
#===========================================
# frontend 영역
# 클라이언트의 요청이 연결될 ip 및 port를 설정
#===========================================
frontend www
bind *:80 # 접속 port 지정
default_backend www.test.com # backend 지정
#===========================================
# backend 영역
# frontend에서 들어온 트래픽을 전달할 프록시 서버들에 대한 설정
# healthcheck 설정
#===========================================
backend www.test.com
mode http # 인스턴스의 실행 모드 또는 프로토콜 설정
balance roundrobin # 로드밸런싱 타입 지정
option httpchk /index.html # index.html 파일의 유무로 healthcheck
option forwardfor # 서버로 전송된 요청에 X-Forwarded-For 헤더 삽입 사용
option http-server-close # 서버 측에서 http 커넥션 종료를 사용
server www1 192.168.0.100:80 check # backend 서버를 선언 "server (name) (ip주소:포트)
server www2 192.168.0.101:80 check # backend 서버를 선언
#===========================================
# Listen 영역
# 모니터링 및 통계 페이지 설정
#===========================================
listen stats
bind 192.168.0.102:8000 # 접속 포트 지정
stats enable # 상태 페이지 활성화
stats uri /status # 접근할 uri 경로
stats refresh 3s # 새로고침 주기 설정
stats auth admin:admin # 상태페이지 접근 인증 추가
2) haproxy 설정파일 검사
$ haproxy -f /etc/haproxy/haproxy.cfg -c
Configuration file is valid
3) haproxy 시작하기
$ systemctl start haproxy
4) haproxy 모니터링 페이지에서 웹서버들의 status 확인하기
- 브라우저를 띄워서 Listen 부분에서 설정한 모니터링 페이지에 접속한다.
- 화면 중간에 www1, www2의 status가 UP으로 보이는 것을 확인 할 수 있다.

4. 웹서버 로그를 통해서 haproxy를 통한 로드밸런싱이 잘 되는지 확인해보기
1) 브라우저에서 www.test.com으로 접속해보기
- www1과 www2가 번갈아 출력되면 정상적으로 로드밸런싱 되는것으로 보면 된다.
2) 웹서버의 access_log 확인해보기
- 로그를 보면 User-agent 값이 없는 로그가 계속 찍히는데, 이것은 Haproxy가 웹서버로 healthcheck를 하고 있는 것이다.
- User-agent 값이 있는 로그는 브라우저에서 test.com를 호출하여 찍힌 로그이며, 소스 IP가 haproxy IP이다.
- 이것은 웹서버의 로그설정에서 x-forward-for 부분을 추가해주면 정상적으로 소스 IP가 보이게 할 수 있다.

3) 웹서버의 로그설정에서 실제 client의 IP를 찍히도록 설정을 변경한다.
- httpd.conf에서 아래와 같이 변경하고 access_log를 확인하면 그림과 같이 소스 IP가 찍히는 것을 볼 수 있다.
- Haproxy 서버의 IP는 안 찍힌다..;;
참고 URL
(before)
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
(after)
LogFormat "%{X-Forwarded-For}i %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
5. Active 서버를 keepalived를 stop하여도 URL 호출이 잘 되는지 확인하기(failover 테스트)
→ Active 서버의 Keepalived와 Haproxy를 stop 시킨 후, VIP로 호출시 www1, www2 가 잘 나오면 정상
→ www1, www2의 access_log를 보면, healthcheck와 브라우저 호출 로그가 잘 찍히면 정상이다.
※ 주의사항
haproxy 설정파일에서 Listen부분은 반드시 VIP를 넣으면 안되고, 각 서버의 IP를 넣어야 한다.
(삽질함..ㅡㅡ)
'Infra > 기타(가상화 등)' 카테고리의 다른 글
| Zabbix 구성-2 (Zabbix Agent)(RHEL7) (0) | 2023.10.26 |
|---|---|
| Zabbix 구성-1 (Zabbix Server)(RHEL8) (0) | 2023.10.26 |
| 서비스 가동률(MTTR, 가용도 등 관련) (0) | 2023.08.31 |
| Network 기본 내용 (0) | 2023.08.13 |
| Haproxy, Keepalived 란? (0) | 2023.07.24 |













